



时间来到了2025年末,DeepSeek发布了最新的V3.2模型,今年可谓是AI算力狂飙的一年,从生成式AI到医学成像远程AI问诊等应用,AI模型参数越来越大,各大大厂的大模型训练都在抢GPU。但是算力的尽头是能源,像英伟达GB200这样超级芯片带来超算的同时产生巨大的能量消耗,迫使单机柜功率从10kW向100kW甚至更高迈进,其背后的能源基础设施也面临着极限压力。如果说GPU是AI的大脑,那么电流就是流淌的血液,没有精准的监测,算力巨人随时可能因供血异常而倒下。
100kW是什么?
过去一个标准42U AI服务器机柜的功率通常在3kW-5kW左右,相当于2台家用挂式空调同时运行。现在的AI算力中心,AI大模型的训练需要多个GPU协同工作,随着NVIDIA Blackwell(如 GB200 NVL72)等架构的问世,从下表(来源NVIDIA官网)可以看出,仅Blackwell单个GPU功耗就达1200W以上,如果部署NVL36或者NVL72(72张GB200),整柜系统的TDP将直接飙升至70kW - 140kW(72×1.4kW=100.8kW)。用直观的对比,一个100kW的机柜,其耗电量可以支撑50个普通家庭的日常用电。
特性 Hopper Blackwell Blackwell Ultra
制造工艺 TSMC 4N TSMC 4NP TSMC 4NP
晶体管数量 800 亿 2080 亿 2080 亿
每个 GPU 的模具 122 NVFP4 稀疏性能 – 10 | 20 PetaFLOPS 15 | 20 PetaFLOPS
FP8 稠密型 | 稀疏性能 2 | 4 PetaFLOPS 5 | 10 PetaFLOPS 5 | 10 PetaFLOPS
注意力加速 (SFU EX2) 4.5 TeraExponentials/s 5 TeraExponentials/s 10.7 TeraExponentials/s
最大 HBM 容量 80 GB HBM (H100)
141 GB HBM3E (H200) 192 GB HBM3E 288 GB HBM3E
最大 HBM 带宽 3.35 TB/s (H100)
4.8 TB/s (H200) 8 TB/s 8 TB/s
NVLink 带宽 900 GB/s 1,800 GB/s 1,800 GB/s
最大功耗 (TGP) 高达 700W 高达 1,200W 高达 1,400W
NVIDIA GPU 芯片比较
以前用交流电(AC)直接进机柜就行,现在 100kW 的功率如果还用低压交流电,电流将高达几百安培,线缆会像大腿一样粗。为了减小损耗,AI 数据中心正全面转向48V甚至更高压的直流(DC)供电。在如此高功率、大电流、直流化的环境下,电流的微小波动都会被放大,任何一次电流检测的失真,其代价都可能是百万美金级的算力宕机。
AI算力配套设施各部位的电流检测需求与技术选型
在100kW以上AI能源链路中,在液冷环境(这个必须)、高频 DC/DC、GPU VRM以及7×24小时连续运行等机房运行条件下,电流检测分布在“发电、配电、用电”的每一个节点,根据不同的环境需求,需要匹配最合适的检测技术:
能源供应端
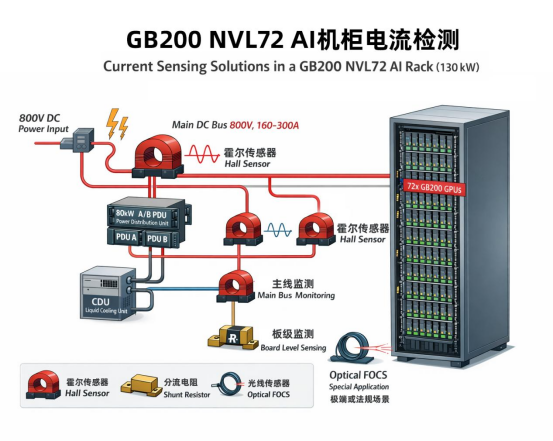
这是电能进入数据中心的第一道门,像GB200 NVL72这种130kW级AI机柜的主流供电是800V DC,母线电流I≈130000/800≈160A,训练负载突变时,达到200-300A并不罕见,于很多采用光伏+储能+变电站组合供电,有的AI算力中心已经部署在深山隧道里,而不是常见的普通机房。这种供电方式测量范围极广,并要求高可靠性和电气隔离,所以霍尔电流传感器成为主流,安装方便,而罗氏线圈(Rogowski Coil) 针对交流大电流检测,体积轻便,无磁饱和风险,适合临时监测或空间极其狭小的变压器输出端。
UPS(不间断电源)与直流屏
这部分属于电源保障端,相当于AI机房的“速效救心丸”,电力切换瞬间电流波动极大,因此要求传感器具有较高的动态响应和温漂控制能力,选型上,闭环霍尔传感器是首选,不缺钱的话可以选择磁通门。闭环霍尔传感器因其零磁通特性和高精度,响应时间也很小,能确保在停电切换时系统不掉线。
PDU机柜配电单元
此部分是配电端,是100kW以上大功率进入机柜后的分流器,一个机柜可能有几十个插槽,需要监测每一路负载。选型主要有芯片级霍尔传感器和分流器,如AN1V体积小,直接PCB安装,适合高密度监控。分流器成本低精度也高适合安装在几十安培的小电流支路上。
服务器电源(PSU)与 DC/DC 转换器
此部分直接为GPU和CPU等高消耗部件供电,要求极高带宽和低损耗,选型上可有:电流互感器(CT)用于交流侧的高频电流检测;精密电阻(Shunt)+ 隔离放大器针对极小电流的精确采样;功率级霍尔芯片:随着GPU功率暴增,越来越多的电源模块开始选用集成式霍尔方案,以解决分流器发热导致的PUE超标问题。
一张表总结电流监测选型
部署位置 检测对象 典型需求 推荐方案 理由
储能/变电 总输入电流 量程大、安全性 开口霍尔/罗氏线圈 安装灵活,大电流+隔离强
UPS/直流屏 备电电流 动态响应、零漂移 闭环霍尔 响应快,保护核心资产
智能PDU 支路电流 体积小、多路采集 芯片级霍尔/分流器 节省机柜空间
服务器电源 输出电流 低损耗、数字化 集成霍尔芯片 降低发热,优化PUE
总结
没有最好,只有最合适,AI算力中心电流监测选型方案也是一样,在选择合适方案之后,仍需注意几点:
1、量程上要留足余量,比如额定电流160-200A,峰值300A,那么选择量程300-500A的传感器型号;
2、隔离耐压是底线,800 V DC 系统隔离耐压 ≥3kV RMS,爬电距离要满足 IEC 62368;
3、看的是“长期漂移”,不是实验室精度数据,NVL72是7×24小时跑模型,不是实验板。温漂、老化、磁饱和裕量,这些比 0.1% 的标称精度更重要。