



2025年末、DeepSeek社が最新のV3.2モデルをリリースした。今年はまさにAIの計算能力が爆発的に伸びた年であり、生成AIから医療画像診断・遠隔AI問診に至るまで、AIモデルのパラメータ数はますます膨大になり、大手企業各社がGPUの確保を競い合っている。しかし、計算能力の果てにあるのはエネルギー問題だ。NVIDIAのGB200のようなスーパーチップは超並列計算を可能にする一方で、莫大な電力を消費する。そのため、1台の標準42U AIサーバーラックの消費電力は従来の10kWから100kW以上へと急上昇しており、その背後にある電力インフラにも限界が迫っている。
もしGPUがAIの「脳」であるならば、電流はその「血液」と言えるだろう。正確なモニタリングがなければ、この巨大な計算能力を持つ巨人は、いつ供給異常によって倒れてもおかしくない。
では、「100kW」とは一体どのような規模なのか?
従来の標準42U AIサーバーラックの消費電力は通常3~5kW程度で、これは家庭用エアコン2台分の電力消費に相当する。しかし現在のAIデータセンターでは、大規模言語モデルの学習には複数のGPUが協調して動作する必要があり、NVIDIA Blackwell(例:GB200 NVL72)などの新アーキテクチャが登場したことで状況は一変した。
下記の表(出典:NVIDIA公式サイト)を見ると、Blackwell世代のGPU 1枚あたりの消費電力はすでに1,200Wを超えている。NVL36やNVL72(72枚のGB200を搭載)といった構成を採用すれば、ラック全体のTDP(熱設計電力)は70~140kW(72 × 1.4kW = 100.8kW)に達する。直感的に言えば、100kWのラック1台で、一般家庭約50世帯分の日常的な電力消費を賄えるほどの規模となる。
| 特性 | Hopper | Blackwell | Blackwell Ultra |
|---|---|---|---|
| 製造プロセス | TSMC 4N | TSMC 4NP | TSMC 4NP |
| トランジスタ数 | 800億個 | 2,080億個 | 2,080億個 |
| GPUあたりのダイ数 | 122 | — | — |
| 疎結合性能(NVFP4) | 20 PetaFLOPS | 15~20 PetaFLOPS | 15~20 PetaFLOPS |
| FP8密結合性能/疎結合性能 | 2/4 PetaFLOPS | 5/10 PetaFLOPS | 5/10 PetaFLOPS |
| アテンションアクセラレーション (SFU EX2) | 4.5 TeraExponentials/s | 5 TeraExponentials/s | 10.7 TeraExponentials/s |
| 最大HBM容量 | 80 GB(H100)、141 GB(H200) | 192 GB HBM3E | 288 GB HBM3E |
| 最大HBM帯域幅 | 3.35 TB/s(H100)、4.8 TB/s(H200) | 8 TB/s | 8 TB/s |
| NVLink帯域幅 | 900 GB/s | 1,800 GB/s | 1,800 GB/s |
| 最大消費電力(TGP) | 最大700W | 最大1,200W | 最大1,400W |
かつては交流(AC)電源をそのままラックに供給すればよかったが、現在100kW級の電力を低圧交流で供給すると、電流は数百アンペアに達し、ケーブルは太ももほどの太さになってしまう。損失を抑えるため、AIデータセンターは現在、48V以上の直流(DC)電源への全面的な移行を進めている。
このような高電力・大電流・直流化された環境下では、電流のわずかな変動も増幅され、電流検出における僅かな誤差が、百万ドル規模の計算停止(ダウンタイム)を引き起こす可能性がある。
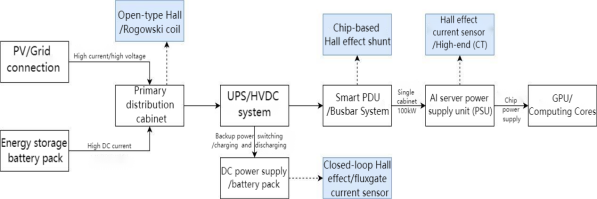
100kWを超えるAI電力チェーンにおいて、液冷環境(必須条件)、高周波DC/DCコンバータ、GPUのVRM(電圧レギュレータモジュール)、そして24時間365日連続稼働といった厳しい条件下で、電流検出は「発電→配電→使用」のすべてのノードにわたって実施される必要がある。それぞれの環境に応じて、最適な検出技術を選定することが求められる。
ここはデータセンターへの電力供給の第一関門となる。例えばGB200 NVL72のような130kW級AIラックでは、主流の供給電圧は800V DCであり、母線電流は
I ≈ 130,000W ÷ 800V ≈ 160A
となる。学習負荷の急変時には200~300Aに達することも珍しくない。最近では、太陽光発電+蓄電池+変電所の組み合わせによる供給方式が一般的で、一部のAI計算センターは都市部のデータセンターではなく、山間部のトンネル内などに設置されているケースもある。
このような広範囲かつ高信頼性・絶縁性が求められる用途では、ホール電流センサが主流となっている。取り付けが容易で、大電流に対応できるためだ。また、交流の大電流測定にはロゴフスキーコイル(Rogowski Coil)が用いられることもあり、これは軽量で磁気飽和のリスクがなく、変圧器出力端など空間が極めて限られた場所での一時モニタリングに適している。
これはAIデータセンターの「救心薬」とも呼べる部分であり、停電時に電源が切り替わる瞬間に大きな電流変動が発生する。そのため、センサには高い動的応答性と温度ドリフト制御能力が求められる。選定としては、クローズドループ型ホールセンサが第一選択肢となる。予算に余裕があればフラックスゲート(磁束門)センサも選べるが、クローズドループ型ホールセンサはゼロ磁束特性と高精度、さらに短い応答時間を備えており、停電時の切り替えでもシステムがダウンしないように保証する。
ここは配電の中継点であり、100kW以上の電力がラック内に分配される箇所だ。1つのラックには数十のスロットがあり、各支路の負荷を個別に監視する必要がある。主な選択肢は、チップサイズのホールセンサ(例:AN1V)とシャント抵抗(分流器)だ。AN1Vは小型でPCB直接実装が可能で、高密度監視に適している。一方、シャント抵抗はコストが低く精度も高く、数十アンペア程度の小電流支路に適している。
この部分はGPUやCPUなど高消費電力部品に直接電力を供給するため、非常に高い帯域幅と低損失が求められる。選定肢としては以下の通り:
| 設置位置 | 検出対象 | 主な要件 | 推奨技術 | 理由 |
|---|---|---|---|---|
| 蓄電池/変電所 | 入力総電流 | 大電流対応、安全性 | オープンタイプホール/ロゴフスキーコイル | 取り付け自由度が高く、大電流・高絶縁性 |
| UPS/直流電源盤 | バックアップ電流 | 高速応答、ドリフト抑制 | クローズドループホール | 応答が速く、重要資産を保護 |
| スマートPDU | 支路電流 | 小型、多チャンネル対応 | チップホール/シャント抵抗 | ラック内スペース節約 |
| サーバー電源 | 出力電流 | 低損失、デジタル対応 | 統合型ホールIC | 発熱抑制、PUE最適化 |
「ベスト」な選択肢はない。あるのは「最も適切」な選択肢だけだ。AI計算センターにおける電流モニタリング技術の選定も同様である。適切な技術を選んだうえで、以下の点にも注意が必要だ:
定格電流に対して十分な余裕を持たせること
例:定格160~200A、ピーク300Aの場合、300~500Aレンジのセンサを選定すべき。
絶縁耐圧は最低ライン
800V DCシステムでは、絶縁耐圧は少なくとも3kV RMS以上、クリープ距離はIEC 62368規格を満たすこと。
「長期ドリフト」を重視せよ。実験室での精度ではない
NVL72は7×24時間稼働で実運用されるものであり、実験ボードではない。温度ドリフト、経年劣化、磁気飽和マージンといった要素は、標称精度0.1%よりもはるかに重要である。